

Shruti Kaushik1,a, Abhinav Choudhury1,b, Nataraj Dasgupta2,c, Sayee Natarajan2,d, Larry A. Pickett2,e, and Varun Dutt1,f
1Applied Cognitive Science Laboratory, Indian Institute of Technology Mandi, Himachal Pradesh, India – 175005
2RxDataScience, Inc., USA - 27709
ashruti_kaushik@students.iitmandi.ac.in, babhinav_choudhury@students.iitmandi.ac.in,cnd@rxdatascience.com, dsayee@rxdatascience.com, elarry@rxdatascience.com, and fvarun@iitmandi.ac.in
Introduction
Since the early ‘90s, machine-learning (ML) algorithms have been used to help mine patterns in data sets concerning fraud detection and others [1]. In recent years, ML algorithms have also been utilized in the healthcare sector [2]. In fact, the existence of electronic health records (EHRs) has allowed researchers to apply ML algorithms to learn hidden patterns in data to improve patient outcomes like the type of medications patients consume and the frequency at which they consume these medications. Mining hidden patterns in healthcare data sets could help healthcare providers and pharmaceutical companiesto plan quality healthcare for patients in need.
To predict healthcare outcomes accurately, ML algorithms need to focus on discovering appropriate featuresfrom data [3]. In general, healthcare data sets are large, and they may contain several thousands of features to enable learning of patterns in data. The presence of many attributes in data sets may make it difficult to discover the most relevant features for predicting outcomes via ML algorithms.
Methodology
Presence of thousands of features in the data is problematic for classification algorithms as processing these features require large memory usage and high computational costs. Two techniques have been suggested in the literature to address the problem of datasets possessing a large number of features: feature reduction (dimensionality reduction) and feature selection[4]. Feature reduction technique reduces the number of attributes by creating new combinations of attributes; whereas, feature selection techniques include and exclude attributes present in the data without changing them [4]. Popular algorithms like Principal Component Analysis (PCA; for features reduction) and Analysis of variance (ANOVA; for features selection) have been used for datasets with a large number of features in the past [5-6]. PCA is a linear feature-based approach that uses eigenvector analysis to determine critical variables in a high dimensional data without much loss of information. ANOVA is a collection of statistical models used to analyze the differences between group means and their associated procedures (such as "variation" between different groups). In ANOVA, the features that describe the most substantial proportion of the variance are the features that are retained in data. Although both PCA and ANOVA approach seem to help in feature discovery, these approaches may become computationally expensive to apply in problems where there are thousands of features in data (e.g., thousands of diagnostic and procedure codes across several patient cases in medical datasets). Another disadvantage of the PCA method is that it is an elimination technique that considers a single feature to be important or unimportant to the problem rather than a group of features being important. Similarly, in ANOVA, researchers need to test assumptions of normalityand independence, which may not be the case when features depend upon each other [10-11]. One way to address the challenge posed by data sets with several thousands of features is by using frequent item-set mining algorithms(e.g., Apriori algorithm) to discover a subset of features because these algorithms look at the associations among items while selecting frequent item-sets [7]. The primary goal of this article is to highlight the potential of Apriori frequent item-set mining algorithm for feature discovery before application of different ML algorithms. Specifically, we take a healthcare dataset involving consumption of two pain medications in the US, and we apply different ML algorithms both with and without a prior feature-discovery process involving the Apriori algorithm. The Apriori algorithm works on the fundamental property that an item-set is frequent only if all its non-empty subsets are also frequent [7]. Using the Apriori algorithm, we generate frequently appearing diagnosis and procedure codes in a healthcare dataset. Then, using these frequently occurring diagnosis and procedure codes as present/absent features, along with other features, we apply certain supervised ML algorithms. We check the benefits of using the Apriori algorithm by comparing the classification accuracies of certain ML algorithms when all attributes are considered as features in the dataset and when only the discovered attributes via Apriori are considered as features. To get confidence in our results, we replicate our analyses using several ML algorithms such as the decision tree, Naïve Bayes classifier, logistic regression, and support vector machine.
Analysis Process
We have used the Truven MarketScan® health dataset containing patients’ insurance claims in the US [9]. The data set contains 120,000 patients, who consumed two pain medications, medicine A, medicine B, or both between January 2011 and December 2015.[1]There were 15,081 attributes present in total against each patient in this dataset. These attributes consist of patients’ age, gender, region, type of admission, diagnoses and procedures performed on the patient, medicine name and its refill information. Out of 15,081 attributes, 15,075 attributes were diagnoses and procedure codes some of which were inter-related. The diagnoses and procedures were written for patients using the International Classification of Diseases (ICD)-9 codes. We applied the Apriori frequent-set mining algorithm to diagnoses made and procedures performed for different patients consuming the two pain medications. The Apriori algorithm discovered the nine frequently appearing diagnoses and procedures among the 15,075 unique diagnoses procedure codes available in the dataset. We used these frequently occurring diagnoses and procedures as input features along with other independent variables in different ML algorithms that were applied to our dataset. The ML algorithms classified patients according to the type of medications consumed (three-class problem) and the frequency of refilling different medications (two-class problem) in the dataset. We used d-primeas measure of accuracy. The higher the d-prime, the better the performance (a d-prime = 0 indicates random performance, where true-positive rate = false-positive rate). In our results, we compared the d-prime value with and without applying Apriori algorithm for features discovery before applying ML algorithms.
Results
We found that the performance of all the algorithms improved with the implementation of
Apriori algorithm. Fig. 1 shows the d-prime results from different ML algorithms for the three-class problems (Fig. 1A) and two-class problems (Fig. 1B) with and without Apriori algorithm implementation. Also, we found that the best d-prime was obtained by the decision tree.
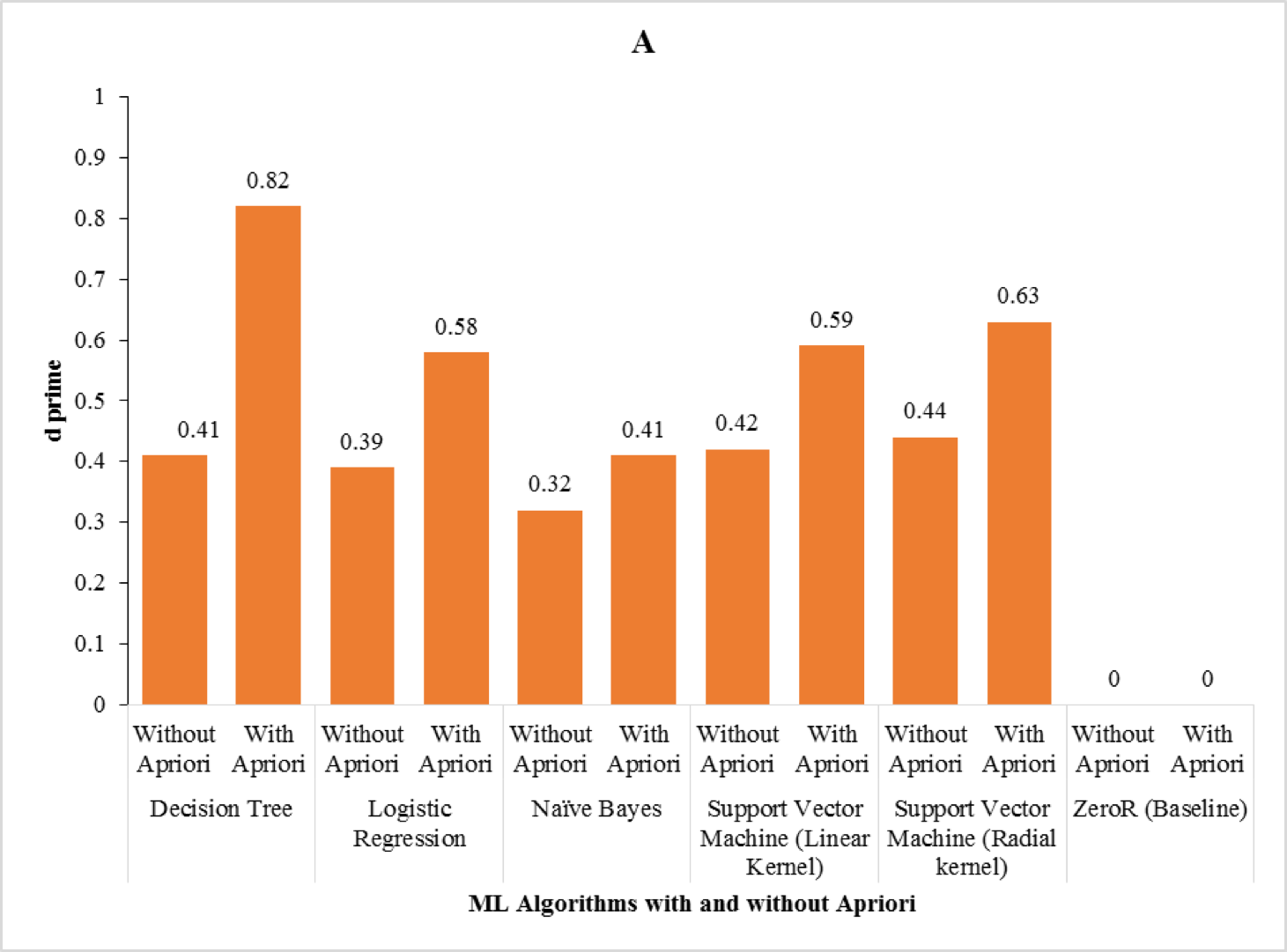
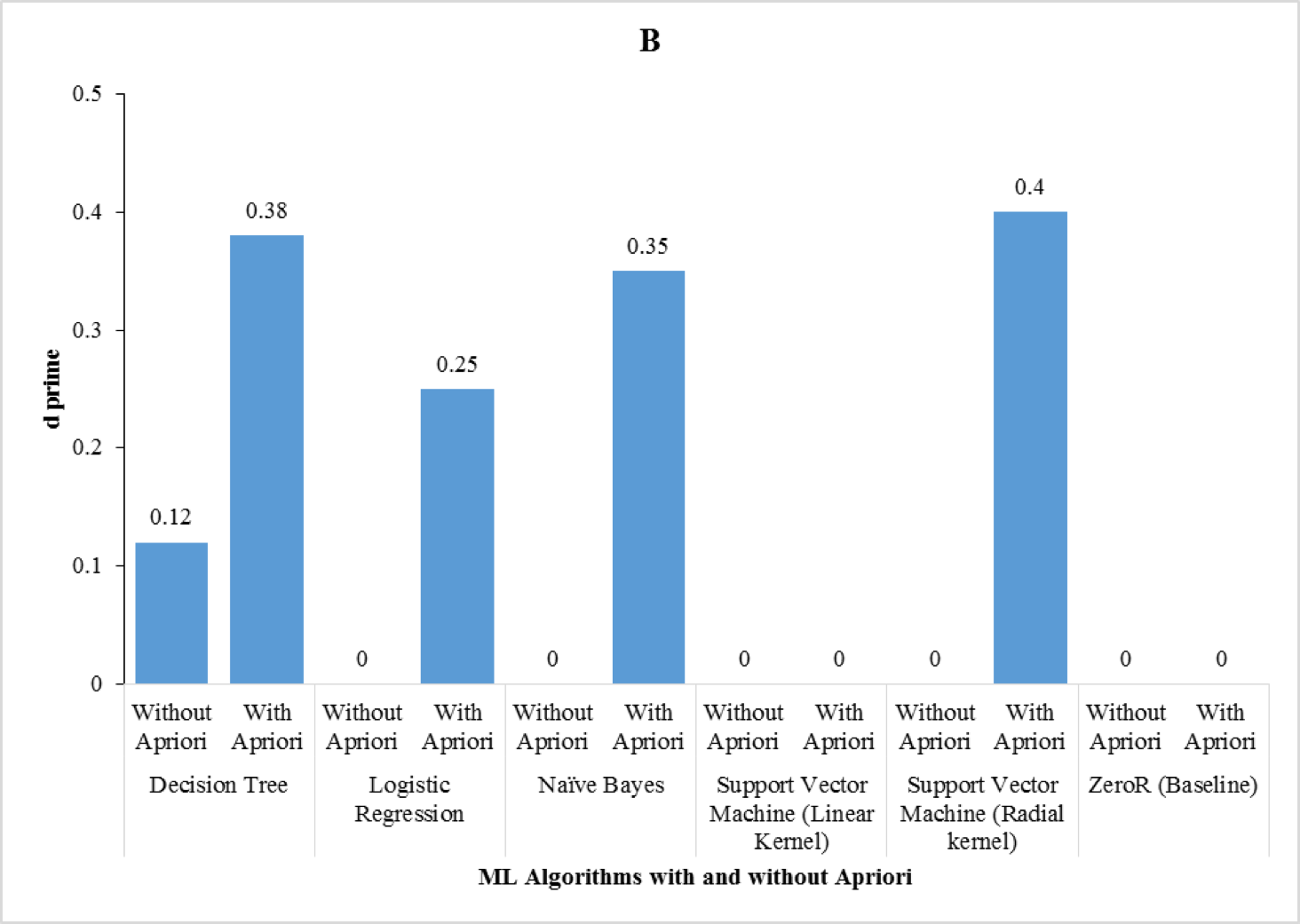
Fig. 1. The d-prime results from different ML algorithms for the three-class problems (A) and two-class problems (B) with and without Apriori algorithm implementation. Source: [12]
Discussion and Conclusions
Apriori algorithm allows us to find features that frequently occur together or are correlated with each other. For example, the nine attributes selected by the Apriori algorithm out of a total of 15,075 attributes occurred in three association rules that possessed the confidence of 99%. Given the high confidence of these rules, the attributes present in them were highly correlated. The most likely reason of decision tree performance is that it implicitly performs feature selection using measures like information gain, and they do not require making any assumption regarding linearity in the data [8].
We believe that predicting the type of medications consumed and their frequency of use could be extremely helpful for pharmaceutical companies to decide upon their drug manufacture strategies. Specifically, such strategies could reduce supply-chain costs by managing the delays in ordering and stocking of medications. Hence, we recommend the use of Apriori algorithm before applications of ML algorithms to discover a subset of features by evaluating the associations among thousands of features in various patients’ records.
This work has been published in the Proceedings of the Springer International Conference on Machine Learning and Data Mining on Pattern Recognition 2018.
Acknowledgements
We are grateful to Nataraj Dasgupta, Madeline Coleman, and Susanna Helton for their kind comments and feedback on a draft version of this article.
References
- Seeja, K. R., and Zareapoor, M.: FraudMiner: a novel credit card fraud detection model based on frequent itemset mining. The Scientific World Journal (2014).
- Oswal, S., Shah, G., and Student, P. G.: A Study on Data Mining Techniques on Healthcare Issues and its uses and Application on Health Sector. International Journal of Engineering Science. 13536 (2017).
- Winters-Miner, Linda A.: Seven ways predictive analytics can improve healthcare, Elsevier (2014).
- Khalid, S., Khalil, T. and Nasreen, S.: A survey of feature selection and feature extraction techniques in machine learning. In Science and Information Conference (SAI), pp. 372-378 (2014).
- Song, F., Guo, Z. and Mei, D.: Feature selection using principal component analysis. In System science, engineering design and manufacturing informatization (ICSEM), international conference onIEEE, Vol. 1, pp. 27-30 (2010).
- Sheikhan, M., Bejani, M. and Gharavian, D.: Modular neural-SVM scheme for speech emotion recognition using ANOVA feature selection method. Neural Computing and Applications, 23(1), pp.215-227 (2013).
- Agrawal, R., and Srikant, R.: Fast algorithms for mining association rules. In Proc. 20th int. conf. very large data bases, VLDB. Vol. 1215, pp. 487-499 (1994).
- : Top 10 Machine Learning Algorithms, https://www.dezyre.com/article/top-10-machine-learning-algorithms/202
- Danielson, E.: Health research data for the real world: the MarketScan® Databases. Ann Arbor, MI: Truven Health Analytics (2014).
- Kim, H.Y.: Analysis of variance (ANOVA) comparing means of more than two groups. Restorative dentistry & endodontics, 39(1), pp.74-77 (2014).
- Kumar, M., Rath, N.K., Swain, A. and Rath, S.K.: Feature Selection and Classification of Microarray Data using MapReduce based ANOVA and K-Nearest Neighbor. Procedia Computer Science, 54, pp.301-310 (2015).
- Kaushik, S., Choudhury, A., Dasgupta, N., Natarajan, S., Pickett, L.A. and Dutt, V.: Evaluating Frequent-Set Mining Approaches in Machine-Learning Problems with Several Attributes: A Case Study in Healthcare. In International Conference on Machine Learning and Data Mining in Pattern Recognition(pp. 244-258). Springer, Cham (2018).
[1]Due to a non-disclosure agreement, we have anonymized the actual names of these medications.
